Data Structures and Algorithms
- File size
- 60.7KB
- Rendered lines
- 1948
Data Structures and Algorithms
Code snippets in Go and Python.
Definitions
- Data structure: ordered collection of data provided by the language or defined and enforced by the programmer
- Algorithm: sequence of steps to solve a problem
- Big \(O\) notation: describes performance of an algorithm as size of the dataset increases
- \(n\): variable representing size of dataset
- Time complexity: time taken for an algorithm to complete execution
- Space complexity: memory taken for an algorithm to complete execution
Big O Notation
- CONSTANT time
- \(O(1)\)
- number of steps for algorithm to complete execution is CONSTANT regardless of size of dataset
// ----- Go implementation -----
func addUp(int n) int{ // computation here has a time complexity of O(1)
var sum int
sum = n * (n + 1)/2
return sum
}
# ----- Python implementation -----
def add_up(n:int) -> int:
sum = 0
sum = n * (n+1)/2
return sum
- LOGARITHMIC time
- \(O(\log n)\)
- number of steps for algorithm to complete execution is MARGINALLY LOWER as size of dataset increases
// ----- Go implementation -----
func binarySearch(arr []int, target int) int { // computation here has a time complexity of O(log n)
left, right := 0, len(arr)-1
for left <= right {
mid := left + (right-left)/2
if arr[mid] == target {
return mid
}
if arr[mid] < target {
left = mid + 1
} else {
right = mid - 1
}
}
return -1 // target not found
}
# ----- Python implementation -----
def binary_search(arr: [int], target:int) -> int: # note that the binary search here assumes a sorted integer array, which affords value comparison below
left_ptr, right_ptr = 0, len(arr) - 1
for left_ptr <= right_ptr:
mid_ptr = (right_ptr - left_ptr)/2 + left_ptr
if arr[mid_ptr] == target:
return mid_ptr
else:
if arr[mid_ptr] < target:
left_ptr = mid_ptr +1
else:
right_ptr = mid_ptr - 1
return -1
- LINEAR time
- \(O(n)\)
- number of steps for algorithm to complete execution INCREASES PROPORTIONALLY to size of dataset
// ----- Go implementation -----
func addUp(int n) int{ // computation here has a time complexity of O(n)
var sum int
sum = 0
for i := 0; i <= n; i++ {
sum += i;
}
return sum
}
# ----- Python implementation -----
def add_up(n:int) -> int:
sum = 0
for i in range(n):
sum += i
return sum
- QUASILINEAR time
- \(O(n \log n)\)
- similar to LINEAR time, but slows down further when working with larger datasets
// ----- Go implementation -----
func mergeSort(arr []int) []int { // computation here has a time complexity of O(n log n)
if len(arr) <= 1 {
return arr
}
mid := len(arr) / 2
left := mergeSort(arr[:mid])
right := mergeSort(arr[mid:])
return merge(left, right)
}
func merge(left, right []int) []int {
result := make([]int, 0)
for len(left) > 0 || len(right) > 0 {
if len(left) == 0 {
return append(result, right...)
}
if len(right) == 0 {
return append(result, left...)
}
if left[0] <= right[0] {
result = append(result, left[0])
left = left[1:]
} else {
result = append(result, right[0])
right = right[1:]
}
}
return result
}
# ----- Python implementation -----
def merge_sort(arr:[int]) -> [int]:
if len(arr) <= 1:
return arr
else:
mid_ptr = len(arr) / 2
left = merge_sort(arr[:mid_ptr])
right = merge_sort(arr[mid_ptr:])
return merge(left, right) # called once
def merge(left:[int], right:[int]) -> [int]: # helper function called once
result = [0]
while len(left) > 0 or len(right) > 0:
if len(left) == 0:
return result.append(right)
if len(right) == 0:
return result.append(left)
if left[0] <= right[0]:
result.append(left[0])
else:
result.append(right[0])
right = right[1:]
return result
- QUADRATIC time
- \(O(n^2)\)
- QUADRATIC increase in number of steps for algorithm to complete execution for a given increase in size of dataset
// ----- Go implementation -----
func bubbleSort(arr []int) { // computation here has a time complexity of O(n^2)
n := len(arr)
for i := 0; i < n-1; i++ {
for j := 0; j < n-i-1; j++ {
if arr[j] > arr[j+1] {
arr[j], arr[j+1] = arr[j+1], arr[j]
}
}
}
}
# ----- Python implementation -----
def bubble_sort(arr:[int]):
for i in range(len(arr)):
for q in range(len(arr)-i):
if arr[q] > arr[q+1]:
arr[q], arr[q+1] = arr[q+1], arr[q] # just swap the values
- FACTORIAL time
- \(O(n!)\)
- extremely slow and rarely used
// ----- Go implementation -----
func factorial(n int) int { // computation here has a time complexity of O(n!)
if n == 0 {
return 1
}
return n * factorial(n-1)
}
# ----- Python implementation -----
def factorial(n:int) -> int:
if n == 0:
return 1
else:
return n * factorial(n-1) # recursive function call
Summary
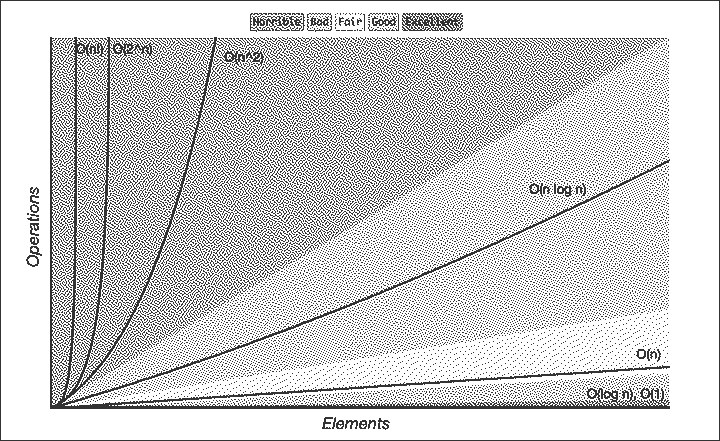
Data Structures
- Stack
- Last-in First-out (LIFO) data structure
push(): appends an element to the TOP of the stackpop(): removes an element from the TOP of the stack- Used in
- undo/redo features in text editors
- moving backward/forward in browser history
- backtracking algorithms (mazes, file directories)
- function call stacks
// ----- Go implementation -----
type Stack struct {
items []interface{} // interface is used here to allow the slice to hold elements of any datatype
}
func (s *Stack) Push(item interface{}) {
s.items = append(s.items, item)
}
func (s *Stack) Pop() interface{} {
if len(s.items) == 0 { // empty stack
return nil
}
index := len(s.items) - 1
item := s.items[index]
s.items = s.items[:index]
return item
}
# ----- Python implementation -----
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
if not self.items: # if empty stack
return None
return self.items.pop()
- Queue
- First-in First-out (FIFO) data structure
add(): enqueues an element to the END of the queueremove(): dequeues an element from the FRONT of the queue- Used in
- keyboard buffers
- printer queues
- priority queues
- linked lists
- breadth-first search algorithm
// ----- Go implementation -----
type Queue struct {
items []interface{} // interface is used here to allow the slice to hold elements of any datatype
}
func (q *Queue) Add(item interface{}) {
q.items = append(q.items, item)
}
func (q *Queue) Remove() interface{} {
if len(q.items) == 0 { // empty queue
return nil
}
item := q.items[0]
q.items = q.items[1:]
return item
}
# ----- Python implementation -----
class Queue:
def __init__(self):
self.items = []
def add(self, item):
self.items.append(item)
def remove(self):
if not self.items: # if empty queue
return None
return self.items.pop(0)
- Priority Queue
- First-in First-out (FIFO) data structure
- SORTS elements by PRIORITY, then dequeues elements of HIGHEST PRIORITY before elements of LOWER PRIORITY
add(): enqueues an element to the END of the queue with a specified value and priorityremove(): dequeues element of HIGHEST priority- Used in
- sorting algorithms (heap sort)
- graph algorithms (dijkstra's algorithm, prim's algorithm)
- system-related functions (load balancing and interrupt handling)
// ----- Go implementation -----
type Item struct { // item being EACH ELEMENT of the priority queue
value interface{} // interface is used here to allow the value to hold elements of any datatype
priority int
}
type PriorityQueue []*Item // priority queue is implemented via a sorted slice of Item elements
func (pq *PriorityQueue) Add(value interface{}, priority int) {
item := &Item{
value: value,
priority: priority,
}
*pq = append(*pq, item)
sort.Slice(*pq, func(i int, j int) bool { // sort the priority queue based on priority
return (*pq)[i].priority < (*pq)[j].priority
})
}
func (pq *PriorityQueue) Remove() interface{} {
if len(*pq) == 0 { // empty priority queue
return nil
}
item := (*pq)[0]
*pq = (*pq)[1:]
return item.value
}
# ----- Python implementation -----
import heapq
class Item:
def __init__(self, value, priority):
self.value = value
self.priority = priority
def __lt__(self, other):
return self.priority < other.priority
class PriorityQueue:
def __init__(self):
self.items = []
def add(self, value, priority):
item = Item(value, priority)
heapq.heappush(self.items, item)
def remove(self):
if not self.items: # if empty priority queue
return None
item = heapq.heappop(self.items)
return item.value
- Linked List
- Collection of nodes that are stored in non-consecutive memory locations (each node comprising a VALUE + pointer(s) to OTHER NODE'S memory address(es))
- SINGLY LINKED LIST
- nodes comprise...
- VALUE
- NEXT node's memory address
- DOUBLY LINKED LIST
- nodes comprise...
- VALUE
- PREVIOUS node's memory address
- NEXT node's memory address
- Used because
- advantageous to arraylists
- faster insertion and deletion of nodes with \(0(1)\) time complexity
- low memory waste
- dynamically allocates memory as required
// ----- Go implementation -----
type Node struct { // type definition for an element in a singly linked list
value interface{} // interface is used here to allow the value to hold elements of any datatype
next *Node // pointer to the next node
}
type LinkedList struct { // type definition for a singly linked list
head *Node // define the head node
}
func (list *LinkedList) append(value interface{}) { // appends a new node to the END of the linked list
newNode := &Node{ // creation of current node
value: value,
next: nil,
}
if list.head == nil { // if linked list empty, make current node the new head node
list.head = newNode
return
}
lastNode := list.head // traverse through the entire linked list until we reach the actual last node in the linkedlist where the next node is nil
for lastNode.next != nil {
lastNode = lastNode.next
}
lastNode.next = newNode // make the current node the new last node
}
func (list *LinkedList) add(value interface{}, position int) error { // adds a new node to a specified position in the linked list
if position < 0 { // if negative index, invalid index
return fmt.Errorf("invalid position") // error
}
newNode := &Node{ // creation of current node
value: value,
next: nil,
}
if position == 0 { // if insert current node at start of linked list, then just point current node's next at the old head
newNode.next = list.head
list.head = newNode
return nil
}
prevNode := list.head // traverse through the entire linked list until we reach the node at the desired position
for i := 0; i < position-1 && prevNode != nil; i++ {
prevNode = prevNode.next
}
if prevNode == nil { // if insert current node at index outside length of the list, invalid index
return fmt.Errorf("position out of range") // error
} else { // assuming no error
newNode.next = prevNode.next // assigns current node pointer to the previousnode's pointer to insert the current node in between the old previous node and its old next node
prevNode.next = newNode // assigns pointer from previousnode to point to current node
return nil
}
}
func (list *LinkedList) remove(value interface{}) error { // remove a node from the linked list by value
if list.head == nil { // empty list
return fmt.Errorf("empty list") // error
}
if list.head.value == value { // check if current list head is node with desired value
list.head = list.head.next
return nil
}
prevNode := list.head // traverse through the entire linked list until we reach the node with the desired value
for prevNode.next != nil && prevNode.next.value != value {
prevNode = prevNode.next
}
if prevNode.next == nil { // if reach the end of the linked list and the node with desired value not found
return fmt.Errorf("element not found") // error
} else { // node with desired value is found and it is the next node
prevNode.next = prevNode.next.next // assigns pointer from current node to one node after the next node, to effectively "remove" it from the linked list
return nil
}
}
func (list *LinkedList) display() { // display all linkedlist nodes
current := list.head // assigns current node to starting node
for current != nil { // traverses through the entire linked list from start to finish
fmt.Printf("%v -> ", current.value)
current = current.next
}
fmt.Println("nil")
}
# ----- Python implementation -----
class Node:
def __init__(self, value):
self.value = value # store value of the node
self.next = None # pointer to the next node
class LinkedList:
def __init__(self):
self.head = None # initialize the head of the list as None
def append(self, value):
new_node = Node(value) # create a new node
if self.head is None: # if the list is empty, set the new node as the head
self.head = new_node
return
last_node = self.head
while last_node.next: # traverse to the last node
last_node = last_node.next
last_node.next = new_node # set the new node as the next of the last node
def add(self, value, position):
if position < 0: # negative index is invalid
raise ValueError("Invalid position")
new_node = Node(value) # create a new node
if position == 0: # if inserting at the head of the list
new_node.next = self.head
self.head = new_node
return
prev_node = self.head
for _ in range(position - 1):
if prev_node is None:
raise ValueError("Position out of range") # index is outside the length of the list
prev_node = prev_node.next
if prev_node is None:
raise ValueError("Position out of range")
new_node.next = prev_node.next # link the new node to the node after the previous node
prev_node.next = new_node # link the previous node to the new node
def remove(self, value):
if self.head is None: # if the list is empty
raise ValueError("Empty list")
if self.head.value == value: # if the head is the node to remove
self.head = self.head.next
return
prev_node = self.head
while prev_node.next and prev_node.next.value != value: # traverse to the node before the one to remove
prev_node = prev_node.next
if prev_node.next is None: # node to remove was not found
raise ValueError("Element not found")
prev_node.next = prev_node.next.next # remove the node by bypassing it
def display(self):
current = self.head # start from the head node
while current: # traverse through the entire linked list
print(f"{current.value} -> ", end="")
current = current.next
print("None") # end the display with 'None'
- Hash Table
- Collection of unique entries that enables fast insertion, lookup and deletion of entries by leveraging on hashing and buckets
- Entry: a key-value pair
- Hashing: computing an integer based on a key (formulas vary depending on the key's datatype) to determine an entry's index
- Collision: when hashing a key returns the SAME index for more than one key
- Bucket: indexed storage location for one or more entries that functions like a LINKED LIST, allowing multiple entries to be stored in cases of collision
- Used because
- best case CONSTANT time complexity of \(O(1)\)
- worst case LINEAR time complexity of \(O(n)\)
- less efficient for smaller datasets
- extremely efficient for larger datasets
// ----- Go implementation -----
type Node struct { // type definition for a node in a hashtable
key string
value string
next *Node
}
type HashTable struct { // type definition for the actual hash table struct
size int
table []*Node
}
func NewHashTable(size int) *HashTable { // initialize a hash table of a specified size
return &HashTable{
size: size,
table: make([]*Node, size),
}
}
func (ht *HashTable) hash(key string) int { // generates an index from a key
sum := 0
for _, char := range key {
sum += int(char)
}
return sum % ht.size
}
func (ht *HashTable) Insert(key, value string) { // insert a new key-value pair into the hash table
index := ht.hash(key)
newNode := &Node{
key: key,
value: value,
}
if ht.table[index] == nil { // handle collisions within the same bucket by implementing a linked list
ht.table[index] = newNode
} else {
current := ht.table[index]
for current.next != nil {
current = current.next
}
current.next = newNode
}
}
func (ht *HashTable) Get(key string) (string, bool) { // retrieve a value based on its key within the hash table
index := ht.hash(key)
current := ht.table[index]
for current != nil {
if current.key == key {
return current.value, true
}
current = current.next
}
return "", false
}
func (ht *HashTable) Delete(key string) { // delete a key-value pair from the hash table
index := ht.hash(key)
if ht.table[index] == nil {
return
}
if ht.table[index].key == key {
ht.table[index] = ht.table[index].next
return
}
prev := ht.table[index]
current := prev.next
for current != nil {
if current.key == key {
prev.next = current.next
return
}
prev = current
current = current.next
}
}
# ----- Python implementation -----
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
class HashTable:
def __init__(self, size):
self.size = size
self.table = [None] * size
def hash(self, key):
# Simple hash function: sum the ASCII values of all characters in the key and modulo by size
return sum(ord(char) for char in key) % self.size
def insert(self, key, value):
index = self.hash(key)
new_node = Node(key, value)
if self.table[index] is None:
# No collision, insert directly
self.table[index] = new_node
else:
# Collision handling: chain nodes in a linked list
current = self.table[index]
while current.next is not None:
current = current.next
current.next = new_node
def get(self, key):
index = self.hash(key)
current = self.table[index]
while current is not None:
if current.key == key:
return current.value, True
current = current.next
return "", False
def delete(self, key):
index = self.hash(key)
current = self.table[index]
if current is None:
return
if current.key == key:
# The node to delete is the first node in the chain
self.table[index] = current.next
return
prev = current
current = current.next
while current is not None:
if current.key == key:
# Unlink the node from the chain
prev.next = current.next
return
prev = current
current = current.next
def display(self):
for i in range(self.size):
print(f"Index {i}:", end="")
current = self.table[i]
while current:
print(f" -> ({current.key}: {current.value})", end="")
current = current.next
print()
Graph
- Non-linear aggregation of nodes and edges
- node: vertex that stores data
- edge: connection between two nodes
- adjacency: relationship between two nodes when they are connected by an edge
- UNDIRECTED GRAPH
- graph with bi-directional adjacency by default
- eg. graph of a social network
- DIRECTED GRAPH
- graph with uni-directional adjacency by default (arrowheads specify direction adjacency flows in), and bi-directional adjacency has to be specified with two seperate arrows
- eg. graph of a street map (some roads only allow one-way traffic)
- graphs can be represented by ADJACENCY MATRIXes or ADJACENCY LISTs as covered below
- Used in
- representing social networks
- visualising network routing
- recommendation engines
- GPS mapping applications
- knowledge graphs
Adjacency Matrix
- 2d nested array of 0s and 1s which acts as a conceptual representation of adjacency between any two nodes in the graph
- Used because
- CONSTANT time complexity of \(O(1)\)
- relatively quicker compared to an ADJACENCY LIST for any given dataset
- QUADRATIC space complexity of \(O(n^2)\)
- less efficient for smaller graph datasets
- extremely efficient for larger graph datasets
// ----- Go implementation -----
type Graph struct { // type definition for an undirected graph represented by an adjacency matrix
vertices int
matrix [][]bool
}
func NewGraph(vertices int) *Graph { // initializes an undirected graph with a given number of vertices
matrix := make([][]bool, vertices)
for i := range matrix {
matrix[i] = make([]bool, vertices)
}
return &Graph{
vertices: vertices,
matrix: matrix,
}
}
func (g *Graph) AddEdge(v1, v2 int) { // adds an undirected edge between two vertices
if v1 >= 0 && v1 < g.vertices && v2 >= 0 && v2 < g.vertices {
g.matrix[v1][v2] = true
g.matrix[v2][v1] = true
}
}
func (g *Graph) PrintMatrix() { // displays adjacency matrix
for _, row := range g.matrix {
fmt.Println(row)
}
}
# ----- Python implementation -----
class Graph:
def __init__(self, vertices):
self.vertices = vertices # Number of vertices in the graph
self.matrix = [[False] * vertices for _ in range(vertices)] # Initialize the adjacency matrix
def add_edge(self, v1, v2):
if 0 <= v1 < self.vertices and 0 <= v2 < self.vertices: # Check if vertices are valid
self.matrix[v1][v2] = True # Add edge from v1 to v2
self.matrix[v2][v1] = True # Add edge from v2 to v1 since it's an undirected graph
def print_matrix(self):
for row in self.matrix: # Print each row of the adjacency matrix
print(row)
- Adjacency List
- Array of LINKED LISTs, where each LINKED LIST head represents a unique node and its adjacent neighbour nodes
- Used because
- LINEAR time complexity of \(O(n)\)
- space complexity of \(O(numVertex + numEdge)\)
- uses less space compared to an ADJACENCY MATRIX for any given dataset
// ----- Go implementation -----
type Node struct { // type definition for a node within an undirected graph
vertex int
next *Node
}
type Graph struct { // type definition for an undirected graph represented by an adjacency list
vertices int
adjList []*Node
}
func NewGraph(vertices int) *Graph { // initializes an undirected graph with a given number of vertices
adjList := make([]*Node, vertices)
return &Graph{
vertices: vertices,
adjList: adjList,
}
}
func (g *Graph) AddEdge(v1, v2 int) { // adds an undirected edge between two vertices
if v1 >= 0 && v1 < g.vertices && v2 >= 0 && v2 < g.vertices {
nodeV1 := &Node{vertex: v2, next: g.adjList[v1]}
g.adjList[v1] = nodeV1
nodeV2 := &Node{vertex: v1, next: g.adjList[v2]}
g.adjList[v2] = nodeV2
}
}
func (g *Graph) PrintList() { // displays adjacency list
for vertex, node := range g.adjList {
fmt.Printf("Vertex %d -> ", vertex)
for node != nil {
fmt.Printf("%d ", node.vertex)
node = node.next
}
fmt.Println()
}
}
# ----- Python implementation -----
class Node:
def __init__(self, vertex):
self.vertex = vertex
self.next = None
class Graph:
def __init__(self, vertices):
self.vertices = vertices
self.adj_list = [None] * vertices # Initialize the adjacency list with None for each vertex
def add_edge(self, v1, v2):
if 0 <= v1 < self.vertices and 0 <= v2 < self.vertices:
# Add the edge from v1 to v2
node_v2 = Node(v2)
node_v2.next = self.adj_list[v1]
self.adj_list[v1] = node_v2
# Add the edge from v2 to v1 (since the graph is undirected)
node_v1 = Node(v1)
node_v1.next = self.adj_list[v2]
self.adj_list[v2] = node_v1
def print_list(self):
for vertex in range(self.vertices):
print(f"Vertex {vertex} ->", end=" ")
temp = self.adj_list[vertex]
while temp:
print(f"{temp.vertex}", end=" ")
temp = temp.next
print()
Tree
- Non-linear collection of nodes (which store data) organised in a hierachy, where nodes are connected by edges
- Root node: top-most node with no incoming edges
- Leaf node: bottom-most nodes with no outgoing edges
- Branch nodes: nodes in the middle with both incoming and outgoing edges
- Parent nodes: any node with an outgoing edge
- Child nodes: any node with an incoming edge
- Sibling nodes: any nodes sharing the same parent node
- Subtree: smaller tree nested within a larger tree
- Size of tree: total number of nodes
- Depth of node: number of edges below root node
- Height of node: number of edges above furthest leaf node
- Used in
- file explorers
- database searches
- domain name servers
- HTML DOM structure
- expression parsing in interpreters and transpilers
Binary Search Tree
- Ordered tree where each parent node has only two child nodes (binary) and each parent node's value is greater than the left child node and smaller than the right child node, including the root node
- Used because
- easier to locate a node when they are ordered within a binary search tree
- best case LOGARITHMIC time complexity of \(O(log n)\)
- worst case LINEAR time complexity of \(O(n)\)
- LINEAR space complexity of \(O(n)\)
// ----- Go implementation -----
type Node struct { // type definition for a generic node within a binary search tree
key int
left *Node
right *Node
}
type BST struct { // type definition for a binary search tree, which begins with its root node
root *Node
}
func NewNode(key int) *Node { // initializes a new node with a given key
return &Node{
key: key,
}
}
func (bst *BST) Insert(key int) { // inserts a key into the binary search tree
if bst.root == nil {
bst.root = NewNode(key)
} else {
insertRecursive(bst.root, key)
}
}
func insertRecursive(node *Node, key int) { // helper function for recursive insertion
if key < node.key {
if node.left == nil {
node.left = NewNode(key)
} else {
insertRecursive(node.left, key)
}
} else if key > node.key {
if node.right == nil {
node.right = NewNode(key)
} else {
insertRecursive(node.right, key)
}
}
}
func (bst *BST) Search(key int) bool { // searches for a key within the binary search tree
return searchRecursive(bst.root, key)
}
func searchRecursive(node *Node, key int) bool { // helper function for recursive search
if node == nil {
return false
}
if key == node.key {
return true
} else if key < node.key {
return searchRecursive(node.left, key)
} else {
return searchRecursive(node.right, key)
}
}
func (bst *BST) InOrderTraversal() { // performs in-order traversal of binary search tree
inOrderRecursive(bst.root)
fmt.Println()
}
func inOrderRecursive(node *Node) { // helper function for recursive in-order traversal
if node != nil {
inOrderRecursive(node.left)
fmt.Printf("%d ", node.key)
inOrderRecursive(node.right)
}
}
# ----- Python implementation -----
class Node:
def __init__(self, key):
self.key = key
self.left = None
self.right = None
class BST:
def __init__(self):
self.root = None
def insert(self, key):
if self.root is None:
self.root = Node(key)
else:
self._insert_recursive(self.root, key)
def _insert_recursive(self, node, key):
if key < node.key:
if node.left is None:
node.left = Node(key)
else:
self._insert_recursive(node.left, key)
elif key > node.key:
if node.right is None:
node.right = Node(key)
else:
self._insert_recursive(node.right, key)
def search(self, key):
return self._search_recursive(self.root, key)
def _search_recursive(self, node, key):
if node is None:
return False
if key == node.key:
return True
elif key < node.key:
return self._search_recursive(node.left, key)
else:
return self._search_recursive(node.right, key)
def in_order_traversal(self):
self._in_order_recursive(self.root)
print() # Newline for cleaner output
def _in_order_recursive(self, node):
if node is not None:
self._in_order_recursive(node.left)
print(node.key, end=' ')
self._in_order_recursive(node.right)
Algorithms
- Linear Search
- LINEAR time complexity of \(O(n)\)
- iterates through a collection one element at a time
- pros
- dataset can be unsorted
- fast for searching small to medium-sized datasets
- useful for data structures without random access
- cons
- slow for large datasets
// ----- Go implementation -----
func linearSearch(arr []interface{}, target interface{}) int { // returns index of target element if found
for i, item := range arr {
if item == target {
return i
}
}
return -1 // returns -1 if target element not found
}
# ----- Python implementation -----
def linear_search(arr, target):
for i, item in enumerate(arr):
if item == target:
return i
return -1
- Binary Search
- LOGARITHMIC time complexity of \(O(log n)\)
- eliminates half of the collection at each step to find the target element
- pros
- more efficient for large datasets
- cons
- dataset has to be sorted
- less efficient for smaller datasets
// ----- Go implementation -----
func binarySearch(arr []interface{}, target interface{}) int {
left, right := 0, len(arr)-1
for left <= right {
mid := left + (right-left)/2
if arr[mid] == target {
return mid // returns index of target element
}
if arr[mid] < target {
left = mid + 1
} else {
right = mid - 1
}
}
return -1 // returns -1 if target element not found
}
# ----- Python implementation -----
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = left + (right - left) * 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
- Interpolation Search
- average time complexity of \(O(log(log n))\)
- worst case LINEAR time complexity of \(O(n)\)
- guesses where a value might be based on estimated probe results, with incorrect probes narrowing the search area and recalculating a new probe
- improvement over BINARY searches that are best used for uniformly distributed datasets
- pros
- more efficient for uniformly distributed datasets
- more efficient for large datasets
- cons
- dataset has to be sorted
- dataset has to be uniformly distributed
// ----- Go implementation -----
func interpolationSearch(arr []interface{}, target interface{}) int {
low := 0
high := len(arr) - 1
for low <= high && target >= arr[low] && target <= arr[high] {
pos := low + ((target - arr[low]) * (high - low)) / (arr[high] - arr[low])
if arr[pos] == target {
return pos // returns index of target element
}
if arr[pos] < target {
low = pos + 1
} else {
high = pos - 1
}
}
return -1 // returns -1 if target element not found
}
# ----- Python implementation -----
def interpolation_search(arr, target):
low = 0
high = len(arr) - 1
while low <= high and target >= arr[low] and target <= arr[high]:
pos = low + ((target - arr[low]) * (high - low)) * (arr[high] - arr[low])
if arr[pos] == target:
return pos
elif arr[pos] < target:
low = pos + 1
else:
high = pos - 1
return -1
- Depth First Search
- search algorithm to traverse a tree or graph one BRANCH at a time
- pick a route
- keep on going until a dead end or previously visited node is reached
- backtrack to last node with unvisited adjacent neighbour nodes
- repeat step 1
- time complexity of \(O(numVertex + numEdge)\)
- LINEAR space complexity of \(O(n)\)
- pros
- utilises a STACK
- child nodes are visited before sibling nodes
- better if destination node is on average FURTHER from start node
- cons
- often returns non-optimal paths
// ----- Go implementation -----
func (g *Graph) DFSUtil(v int) { // helper function for DFS
g.visited[v] = true
fmt.Printf("%d ", v)
for node := g.adjList[v]; node != nil; node = node.next { // recur for all adjacent vertices
if !g.visited[node.vertex] {
g.DFSUtil(node.vertex)
}
}
}
func (g *Graph) DFS() {
for i := 0; i < g.vertices; i++ {
if !g.visited[i] {
g.DFSUtil(i)
}
}
}
# ----- Python implementation -----
class Graph:
def __init__(self, vertices):
self.vertices = vertices
self.adj_list = [[] for _ in range(vertices)]
self.visited = [False] * vertices
def add_edge(self, u, v):
self.adj_list[u].append(v)
def dfs_util(self, v):
self.visited[v] = True
print(v, end=" ")
for node in self.adj_list[v]:
if not self.visited[node]:
self.dfs_util(node)
def dfs(self):
for i in range(self.vertices):
if not self.visited[i]:
self.dfs_util(i)
- Breadth First Search
- search algorithm to traverse a tree or graph one LEVEL at a time
- traverse one node at a time in every direction
- once all directions have been expanded one node, repeat step 1
- time complexity of \(O(numVertex + numEdge)\)
- LINEAR space complexity of \(O(n)\) if implemented with a queue
- space complexity of \(O(numVertex + numEdge)\) if implemented with an adjacency list
- pros
- utilises a QUEUE
- sibling nodes are visited before child nodes
- better if destination node is on average CLOSER to start node
- cons
- less efficient on denser graph datasets with many edges
// ----- Go implementation -----
func (g *Graph) BFS(startVertex int) {
queue := []int{} // initializes a queue for BFS traversal
g.visited[startVertex] = true
queue = append(queue, startVertex)
for len(queue) > 0 {
currentVertex := queue[0]
queue = queue[1:] // dequeues a vertex from the queue
fmt.Printf("%d ", currentVertex)
for node := g.adjList[currentVertex]; node != nil; node = node.next { // check to ensure adjacent vertices have not been visited
if !g.visited[node.vertex] {
g.visited[node.vertex] = true
queue = append(queue, node.vertex)
}
}
}
}
# ----- Python implementation -----
from collections import deque
class Graph:
def __init__(self, vertices):
self.vertices = vertices
self.adj_list = [[] for _ in range(vertices)]
self.visited = [False] * vertices
def add_edge(self, u, v):
self.adj_list[u].append(v)
def bfs(self, start_vertex):
queue = deque()
self.visited[start_vertex] = True
queue.append(start_vertex)
while queue:
current_vertex = queue.popleft()
print(current_vertex, end=" ")
for node in self.adj_list[current_vertex]:
if not self.visited[node]:
self.visited[node] = True
queue.append(node)
- Bubble Sort
- QUADRATIC time complexity of \(O(n^2)\)
- CONSTANT space complexity of \(O(1)\)
- compares pairs of adjacent elements and swaps them if they are not in order
- pros
- relatively fast for small datasets
- lower CONSTANT space complexity since collection sorted in place
- cons
- extremely slow for medium and large datasets
// ----- Go implementation -----
func bubbleSort(arr []int) { // slices are reference types in Go so changes made to the slice within the function are reflected outside the function
n := len(arr)
for i := 0; i < n-1; i++ {
for j := 0; j < n-i-1; j++ {
if arr[j] > arr[j+1] {
arr[j], arr[j+1] = arr[j+1], arr[j]
}
}
}
}
# ----- Python implementation -----
def bubble_sort(arr):
n = len(arr)
for i in range(n - 1):
for j in range(n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
- Selection Sort
- QUADRATIC time complexity of \(O(n^2)\)
- CONSTANT space complexity of \(O(1)\)
- iterates across each element in a collection and compares against and stores the minimum value, swapping variables after each iteration
- pros
- relatively fast for small and medium datasets
- lower CONSTANT space complexity since collection sorted in place
- cons
- slower for large datasets
// ----- Go implementation -----
func selectionSort(arr []int) { // slices are reference types in Go so changes made to the slice within the function are reflected outside the function
n := len(arr)
for i := 0; i < n-1; i++ {
minIndex := i
for j := i + 1; j < n; j++ {
if arr[j] < arr[minIndex] {
minIndex = j
}
}
arr[i], arr[minIndex] = arr[minIndex], arr[i]
}
}
# ----- Python implementation -----
def selection_sort(arr):
n = len(arr)
for i in range(n - 1):
min_index = i
for j in range(i + 1, n):
if arr[j] < arr[min_index]:
min_index = j
arr[i], arr[min_index] = arr[min_index], arr[i]
- Insertion Sort
- QUADRATIC time complexity of \(O(n^2)\)
- CONSTANT space complexity of \(O(1)\)
- compares all elements to the left of a given element, then shift elements to the right to make room to insert a value
- pros
- fast for small and medium datasets
- fewer steps than BUBBLE SORT
- best case LINEAR time complexity is \(O(n)\) compared to SELECTION SORT'S \(O(n^2)\)
- lower CONSTANT space complexity since collection sorted in place
- cons
- slower for large datasets
// ----- Go implementation -----
func insertionSort(arr []int) { // slices are reference types in Go so changes made to the slice within the function are reflected outside the function
n := len(arr)
for i := 1; i < n; i++ {
key := arr[i]
j := i - 1
for j >= 0 && arr[j] > key {
arr[j+1] = arr[j]
j = j - 1
}
arr[j+1] = key
}
}
# ----- Python implementation -----
def insertion_sort(arr):
n = len(arr)
for i in range(1, n):
key = arr[i]
j = i - 1
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
- Merge Sort
- QUASILINEAR time complexity of \(O(n log n)\)
- LINEAR space complexity of \(O(n)\)
- recursively split collection in half, sort each half, then recombine the two halves
- pros
- faster than all sorting algorithms with QUADRATIC time complexity (bubble sort, selection sort, insertion sort)
- cons
- higher LINEAR space complexity since new subarrays are created to store elements for each level of recursion
// ----- Go implementation -----
func mergeSort(arr []int) []int {
if len(arr) <= 1 {
return arr
}
mid := len(arr) / 2
left := mergeSort(arr[:mid])
right := mergeSort(arr[mid:])
return merge(left, right)
}
func merge(left, right []int) []int {
result := make([]int, 0)
for len(left) > 0 || len(right) > 0 {
if len(left) == 0 {
return append(result, right...)
}
if len(right) == 0 {
return append(result, left...)
}
if left[0] <= right[0] {
result = append(result, left[0])
left = left[1:]
} else {
result = append(result, right[0])
right = right[1:]
}
}
return result
}
# ----- Python implementation -----
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) * 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
while len(left) > 0 or len(right) > 0:
if len(left) == 0:
return result + right
if len(right) == 0:
return result + left
if left[0] <= right[0]:
result.append(left[0])
left = left[1:]
else:
result.append(right[0])
right = right[1:]
return result
- Quick Sort
- QUASILINEAR time complexity of \(O(n log n)\) in best case and average case
- QUADRATIC time complexity of \(O(n^2)\) in worst case
- LOGARITHMIC space complexity of \(O(log n)\)
- moves smaller elements in a collection to left side of a pivot element, then recursively divide the collection into 2 partitions
- pros
- faster than all sorting algorithms with QUADRATIC time complexity (bubble sort, selection sort, insertion sort) in best and average cases
- lower LOGARITHMIC space complexity than MERGE SORT'S LINEAR space complexity since collection sorted in place
- cons
- higher LOGARITHMIC space complexity since quick sort relies on recursion
// ----- Go implementation -----
func quickSort(arr []int) { // slices are reference types in Go so changes made to the slice within the function are reflected outside the function
if len(arr) <= 1 {
return
}
pivotIndex := partition(arr)
quickSort(arr[:pivotIndex])
quickSort(arr[pivotIndex+1:])
}
func partition(arr []int) int {
pivot := arr[len(arr)-1]
i := -1
for j := 0; j < len(arr)-1; j++ {
if arr[j] < pivot {
i++
arr[i], arr[j] = arr[j], arr[i]
}
}
arr[i+1], arr[len(arr)-1] = arr[len(arr)-1], arr[i+1]
return i + 1
}
# ----- Python implementation -----
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot_index = partition(arr)
return quick_sort(arr[:pivot_index]) + [arr[pivot_index]] + quick_sort(arr[pivot_index + 1:])
def partition(arr):
pivot = arr[-1]
i = -1
for j in range(len(arr) - 1):
if arr[j] < pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[-1] = arr[-1], arr[i + 1]
return i + 1
Leetcode Algorithms
The below algorithms are often used within Leetcode problems.
- Sliding Window
- Create a fixed-size window that moves through an array and performs a given operation
- Used in problems involving
- substring searches
- subarray slice searches
- Example questions
// ----- Go implementation -----
func findMaxSum(arr []int, k int) int {
windowSum := 0
maxSum := 0
n := len(arr)
if n < k {
return -1 // out of range index error
}
for i := 0; i < k; i++ {
windowSum += arr[i]
}
maxSum = windowSum
for i := k; i < n; i++ {
windowSum += arr[i] - arr[i-k]
if windowSum > maxSum {
maxSum = windowSum
}
}
return maxSum
}
# ----- Python implementation -----
def find_max_sum(arr, k):
n = len(arr)
if n < k:
return -1 # out of range index error
window_sum = sum(arr[:k])
max_sum = window_sum
for i in range(k, n):
window_sum += arr[i] - arr[i - k]
if window_sum > max_sum:
max_sum = window_sum
return max_sum
- Two Pointer
- Two pointers traverse an array simultaneously (from different ends or with a stipulated distance between them)
- Just a glorified way of saying two values are being stored for a given solution
- Used in problems involving
- finding pairs in a sorted array
- merging two sorted arrays
- Example questions
// ----- Go implementation -----
func findPairSum(arr []int, target int) []int {
left := 0 // left pointer index
right := len(arr) - 1 // right pointer index
for left < right {
sum := arr[left] + arr[right]
if sum == target {
return []int{arr[left], arr[right]}
} else if sum < target {
left++
} else {
right--
}
}
return nil // nothing found
}
# ----- Python implementation -----
def find_pair_sum(arr, target):
left = 0
right = len(arr) - 1
while left < right:
current_sum = arr[left] + arr[right]
if current_sum == target:
return [arr[left], arr[right]]
elif current_sum < target:
left += 1
else:
right -= 1
return None
- Three Pointer
- Extension of two pointer algorithm
- Three pointers traverse an array simultaneously (from different ends or with a stipulated distance between them)
- Just a glorified way of saying three values are being stored for a given solution
- Used in problems involving
- finding triplets satisfying a predicate
- merging three or more sorted arrays
- partitioning
- Example questions
// ----- Go implementation -----
func findTriplet(arr []int, target int) []int {
n := len(arr)
for i := 0; i < n-2; i++ {
left := i + 1 // left pointer
right := n - 1 // right pointer
for left < right {
sum := arr[i] + arr[left] + arr[right]
if sum == target {
return []int{arr[i], arr[left], arr[right]}
} else if sum < target {
left++
} else {
right--
}
}
}
return nil // nothing found
}
# ----- Python implementation -----
def find_triplet(arr, target):
n = len(arr)
for i in range(n - 2):
left = i + 1
right = n - 1
while left < right:
current_sum = arr[i] + arr[left] + arr[right]
if current_sum == target:
return [arr[i], arr[left], arr[right]]
elif current_sum < target:
left += 1
else:
right -= 1
return None